
It
is almost certainly not a coincidence that a networking expert at Google has
risen to the top to be put in charge of the infrastructure development at the
search engine, advertising, and now AI model giant. This is particularly true
given that Google has also almost certainly developed the kind of disaggregated
datacenter infrastructure that we have been banging on about for more than a
decade at The Next Platform.
In
such a disaggregated and composable world, networking
is always in the middle of everything, and there is always a need to have a
network that is not just tuned up, but created to do a specific job or set of
jobs so well that it warrants a different network in the first place. This is
particularly true where the components of what would have been a standalone
system are broken apart and trayed up in racks that allow for virtual systems
of varying configurations of compute/memory, I/O, accelerators, and storage,
running from a mix of small systems doing a lot of jobs to one big cluster
doing one big job as necessary. It is not just as simple as putting a bunch of
PCI-Express switches in the racks and trays of compute/memory, I/O, and storage
in the same racks.
The
proliferation of networks and protocols continues across classically distributed
computing and storage, spanning a datacenter, and expands outwards to
connectivity across datacenter regions and around the globe. Here are but a few
examples. Google revealed its homegrown, Linux-based network
operating system, called Snap, and its companion Pony Express data plane engine
in 2019 and has been using this in production since around 2016. Four years ago,
Google revealed that it had created the
Aquila protocol to give InfiniBand-style low latency for relatively small,
tightly coupled clusters as well as a companion Top of Rack in Network
Interface Card, or TiN chip to implement a custom network for clusters that
have 1,000 nodes linked in a dragonfly all-to-all topology. And then there is the
Falcon low latency network interface transport for the “Mount Evans” DPUs
that Google designed in conjunction with Intel.
As
part of the
recent TPU 8 announcements last week, where Google announced a TPU 8i
tailored for inference and a TPU 8t aimed at training, I said we would circle
back and take a look at the new Boardfly configuration of the Inter-Chip
Interconnect that Google invented to cluster together its TPU AI compute
engines with a certain amount – and we are not sure to what level – of memory
coherency across those compute engines. I also wanted to dig into the new “Virgo”
scale out, datacenter-scale Ethernet fabric that Google has created for linking
together racks of machinery, including but not limited to TPU pods.
Up
until now, as you can see in the monster table I originally published in the TPU
8 compute engine story and I am reprinting below for the sake of convenience, the
prior generations of TPU clusters made use of a 2D torus or, for very large
scale machines with thousands of TPUs in a compute pod, a 3D torus interconnect.
Take a gander:

The
torus topology has multiple dimensions, as the name suggests, and have been
popular in some supercomputer architectures – IBM’s BlueGene massively parallel
machines used a 3D torus and the “K” and “Fugaku” supercomputers built by
Fujitsu have a 6D “Tofu” interconnect, just to give two examples. The torus is
great for hooking a lot of gear together, but it is very hard to add new
machines to it. The 2D torus runs out at 256 accelerators, and with the 3D torus
Google used with the “Ironwood” TPU v7e, the connectivity limit pushed as far
as 9,216 accelerators. With the new “Sunfish” TPU 8t training cluster, that
limit has been stretched to 9,600 TPUs in a single system image linked by the
3D torus.
The
torus topology is good for distributed processing, but there are a lot of hops
between devices and that means the latency is high because of the jumps. This
is fine for training, but it is not fine when it comes to inference, where the
one and only goal is to drive down the cost of inference. Inference has a lot
of all-reduce and all-to-all communication, particularly the mixture of experts
(MoE) reasoning models that dominate the licensed models and API services we
see out there in the world.
That
is why the “Zebrafish” TPU 8i is getting the new Boardfly topology, which can
scale to 1,152 interconnected TPU 8i devices in a single memory and compute space
and drop the number of hops down from 16 with the 3D torus of similar capacity
to 7 with the Boardfly configuration. This means that the new
Boardfly
topology – inspired by dragonfly topologies that have become more common in
supercomputing over the past decade and a half – Google is able to push that
ICI network scale for inference up pretty high while dropping the network diameter
by 56 percent and therefore drives the tail latency of data movement down even
more. On average, Google says, the latency of data transmission in the Boardfly
setup is 50 percent lower than on a 3D torus for inference workloads.
That
means that the new Collectives Acceleration Engine (CAE) offload chips on the
Zebrafish TPU 8i devices can be kept fed. The combination of more raw compute
plus the flatter Boardfly interconnect and the CAE units to make it sit up and
bark is why the throughput for GenAI inference has gone up by a factor of three
or higher between Ironwood and Zebrafish.
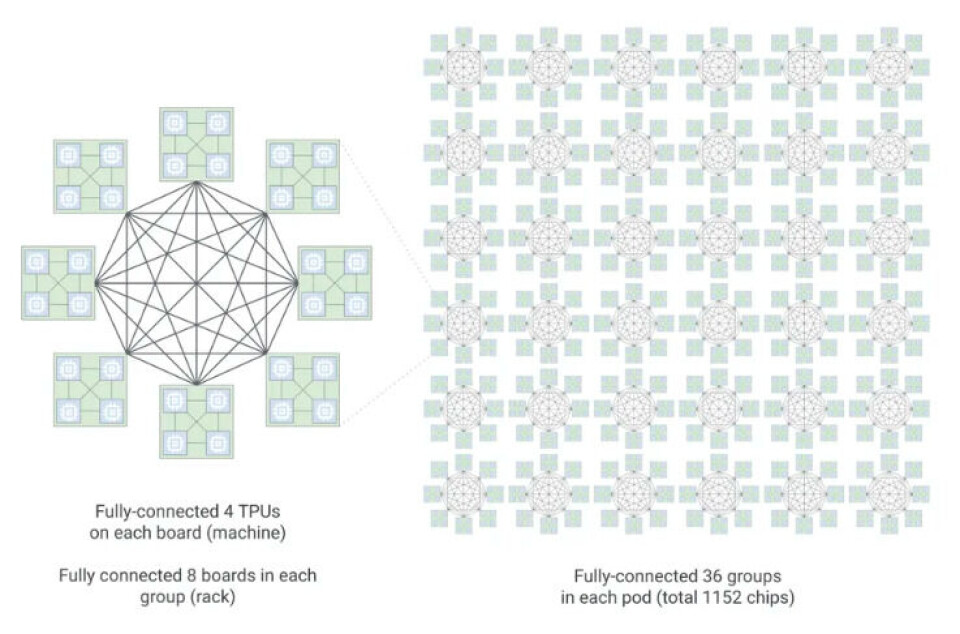
Here
is one rendering of the Boardfly topology:
And
here is another one:
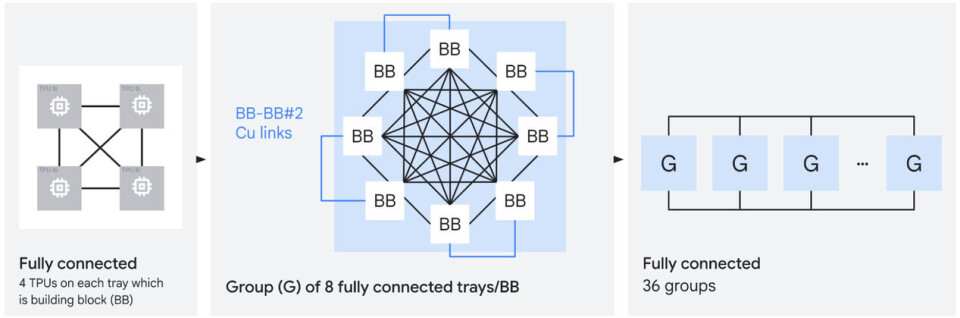
With
Boardfly, the eight TPU 8i chips on the Zebrafish system board are linked in an
all-to-all configuration using ICI ports. Some ICI ports on each device are
left over such that they can be allocated to link together eight boards into a
higher order all-to-all connection, making any of the 32 TPU 8i chips in this
rackscale system able to reach any other TPU in either one or two hops, and
using only copper cables, which are cheap. To get to the full 36 groups of TPUs
with the 1,152 TPUs interconnected, Google uses its “Apollo” optical circuit
switch (part of its Jupiter datacenter network) to provide the links between
TPU groups.
Here
is the worst case hop count across that Boardfly ICI-Apollo OCS network combo:
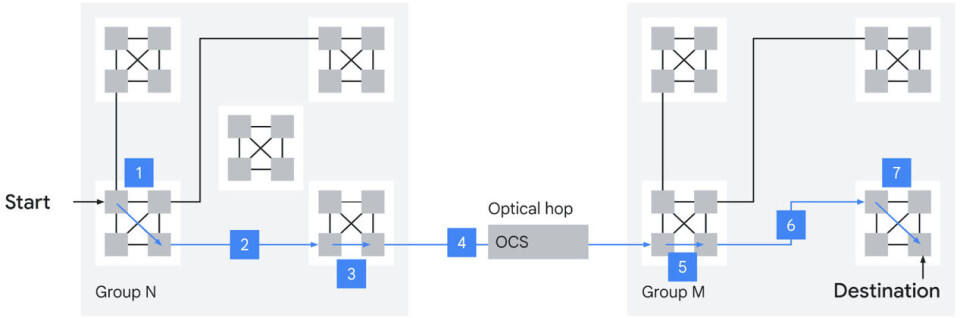
The
reason the ICI-OCS combo can lower the hop count is simple: The OCS switch has
a crazy number of optical ports, and therefore the Zebrafish TPU 8i system
boards can have many more optical transceivers on the board, increasing the
number of light pipes coming off the board. (We don’t know how many more, but
it is probably somewhere on the order of 4X to 8X more links between the 32-way
ICI clusters than was possible with the optical links in the corners of the 3D
torus.
Scaling
Out For AI Training
The
demands of AI training are different, and Google does not want to use the OCS
devices unless it has to. (They are a lot more expensive and rare than an
Ethernet switch based on a Broadcom, Cisco Systems, or Nvidia ASIC.)
Google
is vague about the feeds and speeds for the hardware underneath the Virgo scale
out network that is debuting with the TPU 8t training clusters, but what it has
said is that instead of just focusing on high port speeds, Google is balancing
the bandwidth needs against the desire to have high radix devices (meaning with
lots of ports) that flatten the network (meaning fewer hops once again) as well
as make it less expensive.
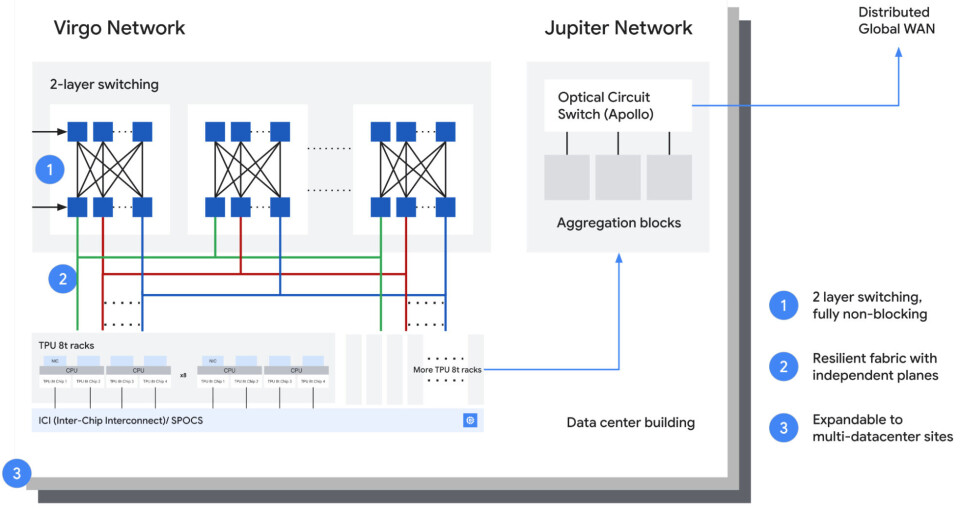
We
do know that the resulting Virgo network delivers a flat, non-blocking, two
layer topology for interlinking racks of accelerators, which can be GPUs or
TPUs. The Apollo OCS switches are not used to scale out AI clusters, but rather
to link to other compute and storage resources in the Google datacenters.
Google
says that the Virgo fabric can interlink as many as 134,000 TPU 8t chips and provide
47 Pb/sec of non-blocking bi-sectional bandwidth in a single fabric. The
company said in a deep dive blog that the Virgo network has 400 Gb/sec per
accelerator on the Sunfish TPU 8t, which is four times the 100 Gb/sec provided
by the port on the Ironwood v7e accelerator for scale out, and says that the
latency is 40 percent lower than the fabric latency of the prior scale out Ethernet
network used with the Ironwood training clusters.
Here
is how Google is building very large TPU training clusters. The Sunfish TPU 8t can
scale to 9,600 compute engines using the ICI in a 3D torus. Using the Virgo
datacenter network, which has all kinds of RDMA enhancements and which we think
is borrowing ideas from the Aquila protocol and the TiN hybrid switch-NIC
chippery, plus extensions to the JAX and Pathways AI frameworks, Google can
scale to 134,000 chips in a single Virgo fabric, and using OCS switches to interlink
Virgo fabrics, Google can stretch that to over 1 million TPUs in a single
logical training cluster.
Last
but not least, Google is adding RDMA support to the TPU 8t and is network
interface cards to create what it calls TPUDirect RDMA and TPU Direct Storage,
which might have a familiar ring to them give that these have long since been
enabled in the Nvidia GPU hardware and software stack:
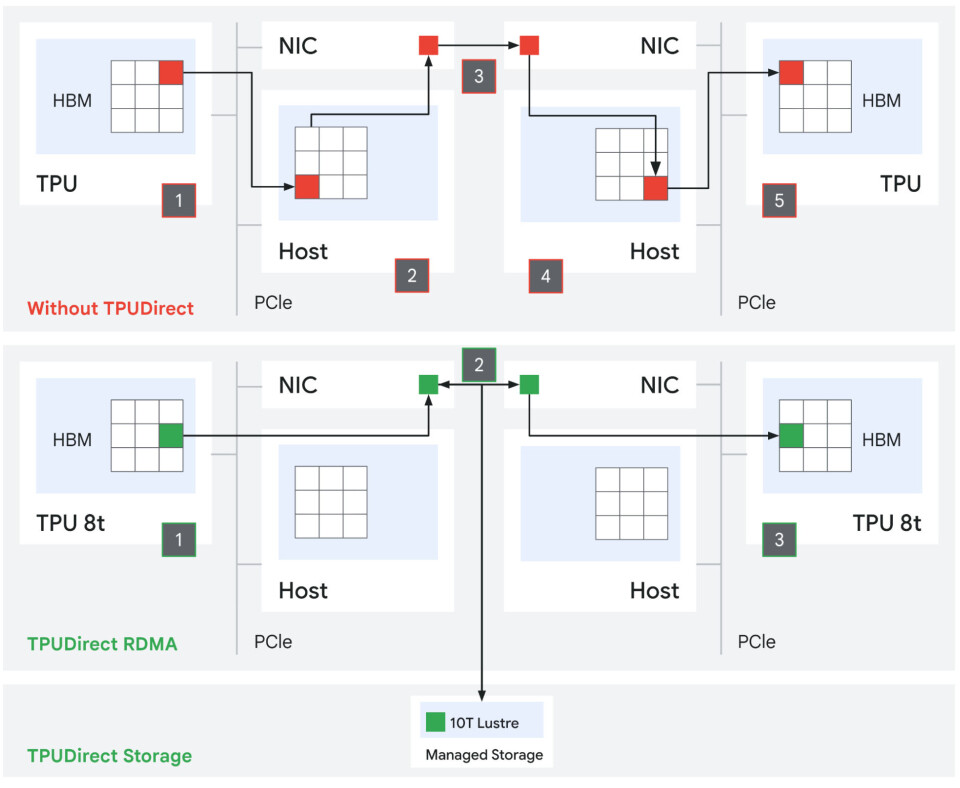
These two new features will no doubt speed up a lot of
AI training, but how much Google did not say much. The company did say that
using TPUDirect Storage with its Managed Lustre 10T storage service boosted storage
access by a factor of 10X compared to not having it on Ironwood TPUs. I was surprised
there was not RDMA for TPU memory and for storage access already.