
Not
everybody has a datacenter that supports liquid cooling, and not every company, particularly those with datacenters inside of major metropolitan areas who legally or practically need their systems all in one place, will ever separate their AI systems from the production systems upon which they
want to build GenAI models and infer against.
Moreover, many companies are doing
classical machine learning as well as GenAI, and in many cases they do not need
rackscale compute nodes to do their inference. And if they need rackscale nodes
for training, they can – and often do – rent them from a big cloud builder or a
neocloud.
This
need to stay on premise for production inference work and small model training is
particularly keen for hedge funds, algorithmic trading companies, and other kinds
of financial services firms who are using machine learning and relatively small
GenAI models to help them make money by analyzing what is going on in markets
and making split-second decisions that humans do not have the processing speed
and reflexes to do. What holds true for FSI firms is equally true of those in
manufacturing, distribution, life sciences, and other industries. They do not have datacenters where you can
drop down a single rack that burns 145 kilowatts and keep it cool. They have to
spread their AI systems out much as they have to do for their general purpose
infrastructure, despite the inefficiencies this entails.
All
of this boils down to there still being a need for air-cooled GPU systems,
something I talked about in detail last summer here
and there.
And to that end, AMD has searched through the bins of its Instinct MI350 series
GPUs and cooked up a half-capacity version of the MI350X that comes in a retro
PCI-Express form factor that can plug into standard server form factors. The
new card is called the MI350P, as you might expect, and it is available now.
We
assumed when we first heard about a future PCI-Express variant of the MI350 series
that this would be a recycling from the bins of finished MI350X and MI355X
parts that are clocked at a uniform 2.2 GHz and had only half their HBM3E
memory stacks working. If AMD was doing a bin sort, you would expect a
distribution of compute cores and HBM memory capacity being sold, not just one configuration.
But the capacity of the MI350P is precisely half of what the MI350X offers. And
that is because the MI350P is a chip package that has half the components in a smaller
socket, and this is done absolutely intentionally so that the device can be air
cooled and still offer all of the benefits of the CDNA 4 architecture that
debuted back in June 2025 with the MI350 Series launch. So it’s a half
package, not a half dud. It looks like this:

The
important MI350 Series features that are common across the lineup include using twelve
high stacks of HBM3E memory as well as the CDNA 4 compute complexes that support
OCP-FP8, MXFP6, and MXFP4 data formats for boosting their effective throughput
of GPUs for both training and inference.
Here
are the specs for the MI350P:

What
is interesting about these specifications (and in contrast to what we see for
the MI300 Series and MI350 Series devices that use the OAM form factor and that
also offer memory coherency across interconnected GPUs and CPUs) is that AMD is
showing delivered actual flops as well as peak theoretical flops at each
precision. We don’t know what benchmark test AMD is using, but the company is
being honest about what to expect from these trimmed down MI350P cards.
As
you can see, on whatever these tests were, the MI350P was able to deliver 90
percent of the 4 TB/sec of peak bandwidth. As for compute, on the 16-bit and
8-bit math, somewhere between 58 percent and 66 percent of peak performance is
being delivered on this test, and MXFP6 is delivering 58 percent as well, but
MXFP4 is only delivering 50 percent of peak.
What
is also interesting in the presentation for the MI350P is that AMD is being
perfectly honest about how it is positioned against not only the air-cooled
system boards based on the MI350X and MI355X GPUs that are the flagship GPUs
from the company, but how you position the MI350P against running classical machine
learning and GenAI inference on Epyc GPUs and Radeon AI Pro cards, including
suggested AI model size limits based on the memory and compute:
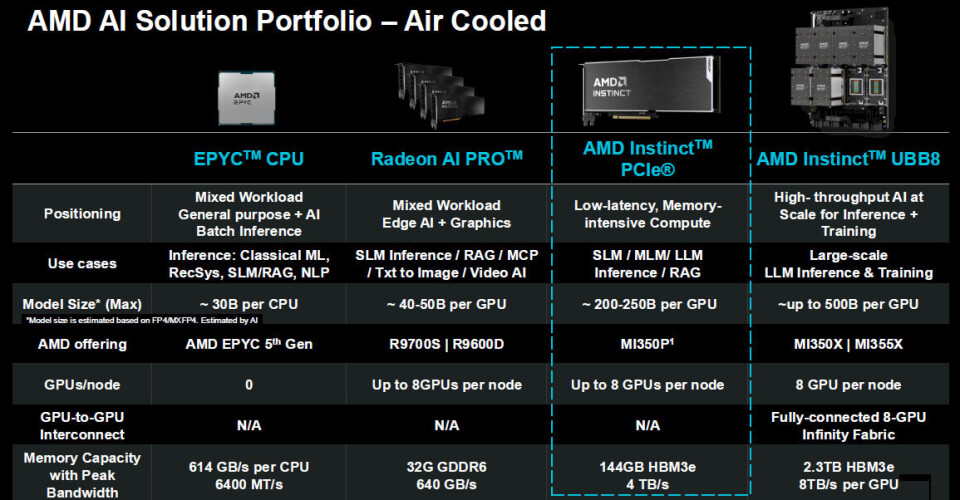
The
sweet spot for the MI350P is for models that have around 200 billion to 250
billion parameters, which is a perfectly reasonable size model commonly used in
the enterprise to augment all kinds of data processing and transaction
processing.
I
like to take a broad historical view of compute engines, and to that end below
is a monster table that shows the entire Instinct GPU line since the
MI25 was launched way back in the summer of 2017.
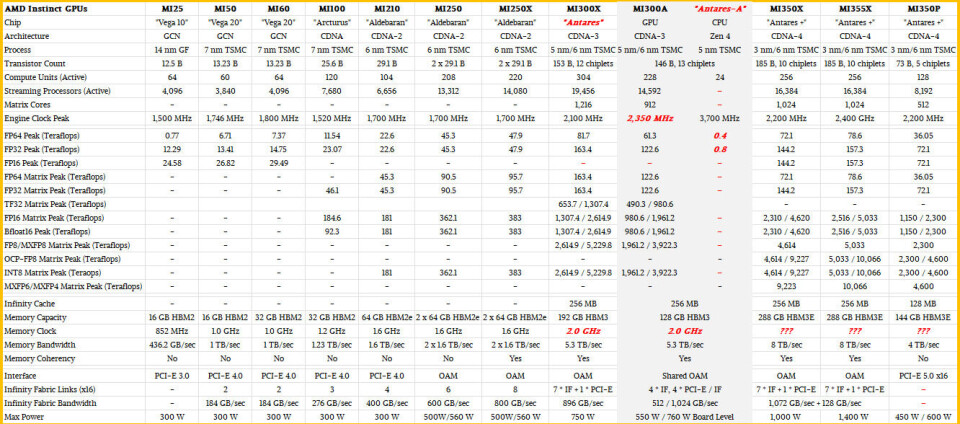
On
interesting thing about the MI350P is that it can be geared down for environments
or server enclosures that cannot take a lot of heat. The peak performance specs
shown for the MI350P in the tables above assume that you are running the GPU at
2.2 GHz and that the system can dissipate a maximum of 600 watts of heat. But
there is a way to throttle the MI350P back to 450 watts, which is a 25 percent
reduction in power, and I think that is probably only a reduction of 10 percent
to 15 percent in performance, which means it is probably only dropping down to
1.9 GHz to 2 GHz on the clock speed. On workloads that are memory bandwidth sensitive,
the reduction in actual, real-world performance could be less than 10 percent
since the memory speed is not being geared down (as far as I can tell) and the
capacity is not being capped, either.
Given
the need for better price/performance per watt, it is reasonable to expect many
of the customers that the MI350P is aimed at to go for the 450 watt downgrade –
and it is also reasonable to expect them to want to pay around 10 percent less
than their negotiated price off of whatever list price is for these devices.
The
usual suspects of OEMs and ODMs are lined up to make systems based on the
MI350P, presumably with one or two “Genoa” Epyc 9004 or a “Turin” Epyc 9005 CPU
acting as host processor for four or eight of these MI350Ps in a single node.
Dell is putting together PowerEdge XE7745 and PowerEdge R7725 rack servers with
the MI350Ps, and Hewlett Packard Enterprise is adding them to the ProLiant
DL385 and 385a Gen 11 servers as well as the ProLiant DL345 Gen 12 servers.
Lenovo is adding them to the ThinkSystem SR675/I v3 machines, and Cisco Systems
is putting them into its C845a M8, X Series 580p, and UC245 M8 servers.
Supermicro is rounding out the OEMs with its AS -5126GS-TNRT, AS -5126GS-TNRT2,
AS -2026HS-TN, and AS -2116CS-TN machines. I strongly suspect that these will
be as scarce as hound’s teeth, just like all GPUs are today.
Pricing was not announced for the MI350P, but it
should be a little less than half of whatever the price is for the MI350X,
which supports memory coherency across the GPUs and into the CPUs while the
MI350P cannot even have two-way coherency across GPUs. The MI350P is absolutely
and only standalone, no matter how many you put into the machine.