
It
is very hard to guess what an AI compute engine should look like five years
into the future, other than the obvious more, more, more. And when AI
models are changing faster than chip development cycles, any of the big model
builders as well as anyone running AI inference at scale has to have a multi-product,
multi-source, and multi-supplier strategy to hedge against any delay or needed
feature in a future AI compute engine.
If
you squint your eyes and look at Meta Platforms, its business is to run ranking
and recommendation engines atop vast social networks that include vast amount
of custom content created by users. These R&R applications were collections
of algorithms running on vast fleets of CPUs, and eventually they were
augmented by machine learning algorithms that ran on GPU accelerators – what
are called deep learning recommendation models, or DRLMs.
These
DLRMs are very different animals than the large language models created by
Google, OpenAI, and Anthropic, and they required very different hardware. DLRMs
turn their data into vectors, just like LLMs do, but they create a giant, multidimensional
vector space that can be used to show how things might be related – someone on
Facebook who likes cat videos and new cat videos added to Instagram, to use an
obvious example – without having a graph algorithm that literally links them.
In this sense, it is predictive, not deterministic, and that is a very powerful
thing for one of the world’s largest advertisers to be able to do.
The
trouble is, creating a memory space that is big enough for billions of users
doing trillions or tens of trillions of things is a tall order, even when you
boil reality down to a bunch of floating point vectors so you can make correlations
and presume relationships, it sure do mount up quick. Meta Platforms decided to
split the job into two pieces: GPUs with fast HBM hold relevant parts of the
embedding tables that are “hot” and the rest are dumped off to CPUs with fat DRAM
hold the rest. I went through this in detail with a drilldown on the “Zion” and
“ZionEX” and “Grand Teton” hybrid CPU-GPU systems designed by Meta Platforms way
back in October 2022, showing how the DLRMs were just as parameter-intense
and flops-hungry as the LLMs of the time. I also detailed how Meta Platforms had
created what amounts to a memory hypervisor, called “Neo,” that stages
parameters and embeddings not only across the CPU and GPU memory hierarchies
within a node, but also across a cluster of machines.
What
is clear is that Meta Platforms was very good at architecting DLRM systems
running R&R training and R&R inference, but it did not control its fate
even one little bit when it came to the compute engines it would use. In a very
real sense, the advent of the “Grace” CG100 Arm server CPU with fat and fast
NVLink ports to share memory coherently with Nvidia “Hopper” H100 GPUs was an
effort to keep Meta Platforms in the Nvidia fold. DLRMs needed CPU memory a
whole lot more than LLMs do, which do not have giant embedding tables.
The
big problem is that DLRMs do not scale up their improvement as more compute is
thrown at them, which means that a bigger DLRM is not always a better DLRM. Starting
in 2024, however, Meta Platforms started talking about a new approach to DLRMs,
which is called generative recommenders and based on a technique called Hierarchical Sequential Transduction
Unit (HSTU), that borrowed some of the techniques of LLMs and basically
treats user activity as a language and uses generative techniques to predict
the next thing you will do, just like an LLM can predict the next token in a sequence
based on the corpus of human knowledge. This HTSU method is embedded in the
DLRM v3 models Meta Platforms uses across its application platforms.
I
happen to think that this insight, to make DLRMs more like LLMs, and whatever
algorithms and math underlie the HSTU technique and its generative
recommendation engine, are driving the MTIA AI compute engine effort at Meta
Platforms. The only reason to create a homegrown AI compute engine is to do the
codesign that delivers a radical improvement in bang for the buck. (It is
arguably easier to be less costly than a GPU than it is to be better at a given
parallel computing task, so this is no mean feat.)
Meta
Platforms recently talked about its MTIA roadmap, putting the kibosh on idle
talk that it was floundering and backing up comments made by its chip partner,
Broadcom. After pondering the MTIA roadmap a bit, I finally have some thoughts worth
writing down. We don’t know much about the future MTIA devices, but you can bet
one thing for sure: They will be co-designed to employ this HTSU technique and
help drive down the cost of both R&R training and R&R inference. We
also think that the HTSU approach means that future MTIA devices could be
pretty good at GenAI inference, helping Meta Platforms kill two birds with one
architecture stone, supporting its DLRM and its LLM efforts.
Let’s
Take A Look Under The Hood
The
roadmap reveal by Meta Platforms is here,
in case you missed it.
What
is immediately obvious is that the future MTIAs look a whole lot more like GPUs
and other XPUs than the prior MTIA
v1 launched in May 2023 and MTIA
v2 launched in April 2023. We have renamed these the MTIA 100 and MTIA 200,
and Meta Platforms says that it has deployed hundreds of thousands of these and
as well as the MTIA 300, which it has not talked about until now, in its
datacenters.
The
reason why the future MTIAs as well as the current MTIA 300, which has been
deployed for R&R training workloads, need to look like GPUs and AI XPUs
because they are shifting away from an application based on embedding lookups
and comparisons for user and activity correlations in a vector embedding space to
user activity prediction akin to token prediction in an LLM. So of course you
need wicked fast memory as well as a lot more compute to use the HTSU method in
DLRM v3 versus the machine learning techniques in DLRM v2.
Meta
Platforms has been deploying the MTIA 300 compute engines since sometime in the
second half of last year. Here are the simplistic block diagrams that Meta
Platforms gave out, all strung together side by side so you can see them all at
once:

The
MTIA 300 is a multichip design, unlike the MTIA 100 and MTIA 200, which were
monolithic dies that had compute, I/O, and memory controllers all on the same
piece of silicon. The MTIA has a grid of processing elements that connect to
banks of what I think is, for economic reasons, HBM3 (not HBM3E) stacked
memory. The capacity and bandwidth numbers that Meta Platforms gave out sure
make me believe that.
Anyway,
as you can see, the MTIA had one compute chip that had HBM3 controllers on it
and two I/O chiplets, one top and one bottom, to hook out to the world. Notably,
there are a combined dozen lanes of 800 Gb/sec RoCE Ethernet coming off those two
I/O chips, which is a fair amount of bandwidth.
As
is my habit, I created a table that shows the six different MTIA compute
engines side by side so we can compare the past to the future. Take a look and
we will talk this out:
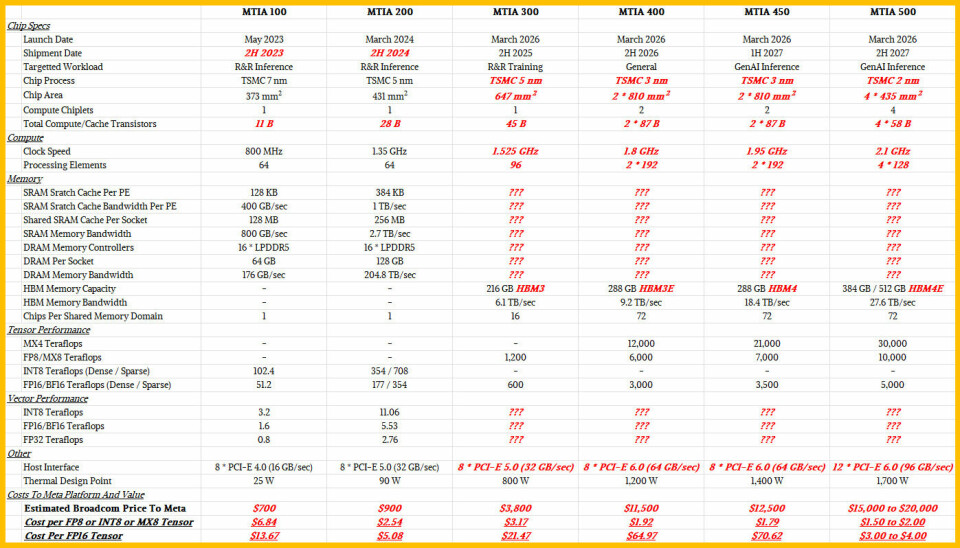
As
is usual at The Next Platform, anything in regular black text is real data
and anything in bold red italics text is an estimate from me.
With
the MTIA 300, Meta Platforms shifted from the INT8 processing to FP8
processing, which means data conversion to integer from floating point formats
is no longer necessary. The tensor units on the MTIA 300 had a pretty
significant performance boost, but they also burned 8.9X as much electricity.
Our best guess is that they cost more per 8-bit or 16-bit unit of performance,
but that was a given because the MTIA 300 is focused on R&R training and
not R&R inference like the MTIA 100 and MTIA 20 were. MTIA 300 was also
laying the groundwork for much more powerful MTIA compute engines.
What
we do not know is how much vector performance is in the MTIA 300 and its
successors, but as our architectural deep dive went into, each processing
element has two RISC-V vector cores. Perhaps Meta Platforms will enlighten us?
You
can see that the MTIA 400 doubles up the number of compute dies in a socket, and
adds a die-to-die link to an SoC that acts as a bridge between the host
processor and the MTIA processing
elements. We presume that host processor is
Arm’s new AGI CPU-1, given that Meta Platforms is the co-designer of that
CPU and its first customer. Exactly what this SoC is and does is unclear, but
we would have expected it to be wedged between the MTIA compute and its I/O
dies, like a DPU of sorts. The MTIA 400 will plug into the “Helios” Open Rack
Wide v3 rack that was co-developed by AMD and Meta Platforms and up to 72 of
these devices will plug together into a shared memory domain.
Meta
Platforms says that the MTIA 400 is done testing in its labs and it is getting
ready to deploy it inside of its datacenters. Which has Broadcom, its chip
shepherd and possibly its rackscale system builder, very happy indeed.

The
MTIA 450 is a fast-following upgrade to the MTIA 400, we think moving from the
HBM3E memory used in the MTIA 400 to HBM4 memory. That doubles up the memory
bandwidth on the devices to a very respectable 18.4 TB/sec against a 1.75X
increase in peak MX4 throughput. It is interesting to note that MX8 and FP16 performance
with the MTIA 450 only rises by 16.7 percent compared to the MTIA 400. My guess
is that, for whatever reason, this extra performance is latent in the MTIA 400
and MTIA 450 dies and is not being exposed for some reason, perhaps related to
yield on 3 nanometer processes from Taiwan Semiconductor Manufacturing Co. Such
dark silicon bothers me, particularly when Meta Platforms has no commercial reason
to keep sections of the chip dark except if it helps yield.
It
is harder to figure what the MTIA 500 is, but it clearly has four chips for
processing element compute. I think that moving to four chiplets at the end of
next year is a dry run for creating a four-die compute complex ahead of the
inevitable shift to High NA processes that come to add more transistors to
chips but at a reticle area that is cut in half. If I were doing this, I would
use current EUV processes and die interconnects at the 2 nanometer node to
perfect getting yield on four-die packages and then be ready for the High NA
jump. This would be particularly interesting in that a smaller chip has better
yield, which is why AMD shifted to eight-die GPU complexes two years ago.
Better to learn this chiplet gluing separate from the High NA jump.

You
will note that the MTIA 500 will have versions with 384 GB or 512 GB of stacked
memory, which we think based on the specs will be HBM4E. The 384 GB version is
very likely a yield play – why on Earth would anyone toss out an MTIA 500 where
only 25 percent of its memory is a dud? Broadcom wants to sell it and Meta
Platforms wants to buy it. I think there will be a 256 GB variant for the same
reason, by the way.
We took a wild stab at estimating the cost of finished
MTIA compute engines from Broadcom for Meta Platforms, just to illustrate how
quickly the technology and the economics will change. From 2023 to 2027, Meta
Platforms will increase the effective throughput of its MTIA devices by 293X
(with half of that coming from a move to MX4 4-bit data formats) and as best as
I can guess, and its cost per unit of inference throughput, as gauged in peak
flops, will have come down by 9.1X.