
For years, co-founder and chief executive officer Jensen
Huang and other higher-ups at Nvidia have been banging on the message that the
company is more than its GPUs, that the chips that have become crucial to the
rapid expansion of AI over the past several years are key parts of a larger
platform story that also comes with other processors, networking, storage,
software, reference architectures, AI models, and more.
Huang drove home that point several times during this
two-plus hour keynote at Nvidia’s
GTC 2026 conference last month in San Jose, California, and the mantra could
be heard in other rooms and hallways of the San Jose McEnery Convention Center.
That said, it’s not difficult to understand why, when thinking about Nvidia,
the focus tends to fall on the GPUs. The company started out in 1993 as a GPU
maker, and for more than a decade has led the charge to the top of the AI heap with
those chips firmly in hand
Nvidia’s CUDA computing platform and programming model
opened the door for the GPUs to move beyond its graphics rendering roots and
into general-purpose computing in the datacenter, the NVLink
interconnect enabled fast communication directly between GPUs, and newer
software innovations like Dynamo – an open, distributed inference framework –
all play key roles in Nvidia’s platform push, but it’s the compute
complexes like Grace Blackwell today and the upcoming
Vera-Rubin compute complex slated for later this year – and eventually
the follow-on to that, the Vera-Feynman platform – that gets people jazzed.
They are also the key drivers behind the eye-watering
revenue numbers Nvidia generates. The company ended its FY 2026 with $215.9
billion in revenue, a 6.5 percent year-over-year jump, and include $68.1
billion in the FY fourth quarter that ended in January. In all, Nvidia’s
datacenter revenue was $193.7 billion and $62.3 billion, respectively.
But behind those GPU-driven numbers are the innovations
behind the GPUs themselves, and Nvidia executives are pushing the point again
this week in the wake of what they say are record-setting AI inference
performances on MLPerf benchmarks.

The vendor’s co-design strategy that includes hardware,
software, and AI models is what drove the AI inference performance numbers in
such measures as minimum token rate and shorter time to the first token,
according to Dave Salvatore, director of accelerated computing products for
Nvidia. The company no doubt delivers powerful GPUs to run power-hungry AI and
agentic AI workloads, but it’s the advances in software that is making much of
the different, he told The Next Platform.

“People point at Nvidia and go, ‘Well, Nvidia because they
have these great GPUs. We do have amazing GPUs,” Salvatore said. “The
technology and the architectural innovations that we are making in our GPUs
really represent the leading edge of what’s possible for AI. There is a
tendency with Nvidia to just think about our GPUs. But we are a datacenter
platform company, which means GPUs are just the beginning.”
Nvidia also has brought in outside help, through its $20
billion “acquihire” in December of startup Groq’s development team and the
licensing deal for its LPU engines for AI inferencing, a deal that began to
show its fruits at GTC.
MLPerf is an industry standard run by the MLCommons
Consortium, and the latest results were run on the MLPerf Inference v6.0
benchmark suite, which includes datacenter tests that are either new or
updated. The tests in green below are new, according to Salvatore.

The new tests included DeepSeek-R1 Interactive that tested
token deliver speed and reduced time to first token, the GPT-OSS-120B, a
mixture-of-experts reasoning model, and Qwen3-VL-235B-A22B, a multimodel
vision-language mode. Some were tested in multiple environments, as seen below:
offline, server, and interactive.
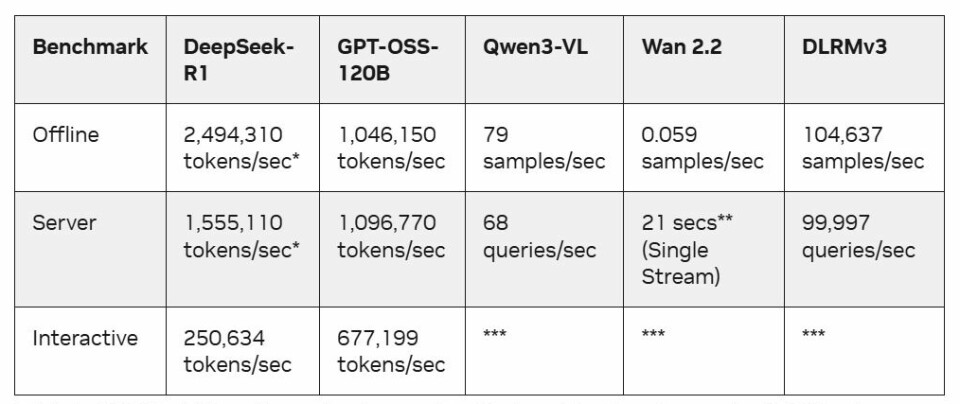
“These different workloads really are a good representation
of a lot what’s happening out there in the market in terms datacenter AI,” he
said. “An important thing that the consortium understands the speed which this
market is moving and understand, In version 6, there was a concerted effort to
update the workloads and bring them forward to better align to where the market
is today.”
The tests largely address inferencing, which Nvidia
executives arguing has overtaken training as the primary AI and agentic AI
workload. For large language models (LLMs) and reasoning models, the coin of
the realm are tokens – Huang last month called them the “new commodity” – and token
generation, both the speed and the cost, are bottom line for vendors. Salvatore
echoed Huang’s argument made at GTC, that Nvidia’s platforms – while expensive
– improves token generation.
“Increases in token generation or increases in performance
basically generate more revenue, they reduce costs, they get you more value
from the same infrastructure,” he said. “This is the ‘so what’ of the
performance from these latest MLPerf results.”
Nvidia used systems built on its Blackwell Ultra GPUs – and
with 14 partners, from OEMs like Dell Technologies and HPE to cloud services
providers such as Google Cloud – submitting results. The Nvidia-powered systems
delivered the highest token throughput in a range of workloads.

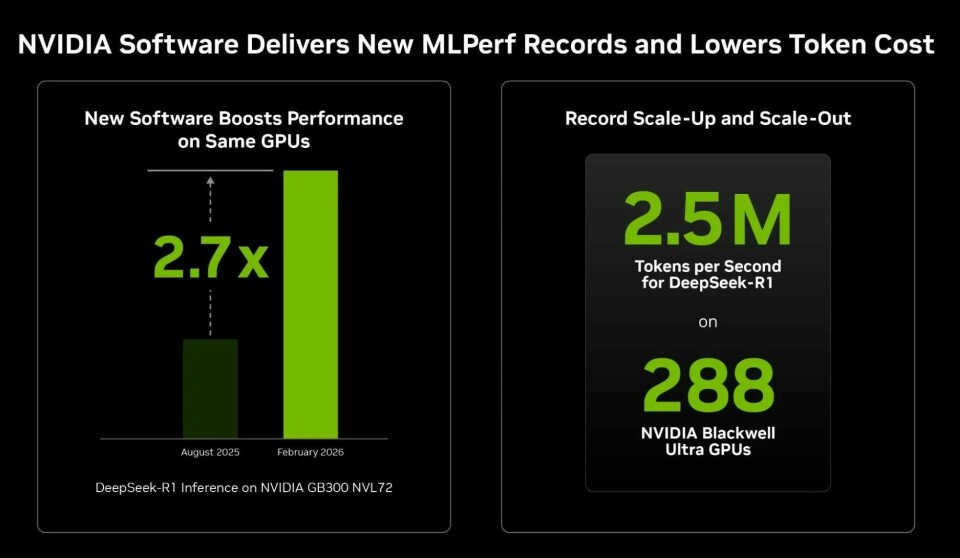
The company also noted speed improvements with the GB300
NVL72 v6.0 over v5.1, ranging from 1.21 times in the Llama 3.1 405B offline
benchmark to 2.77 times for DeepSeek-R1 server test.
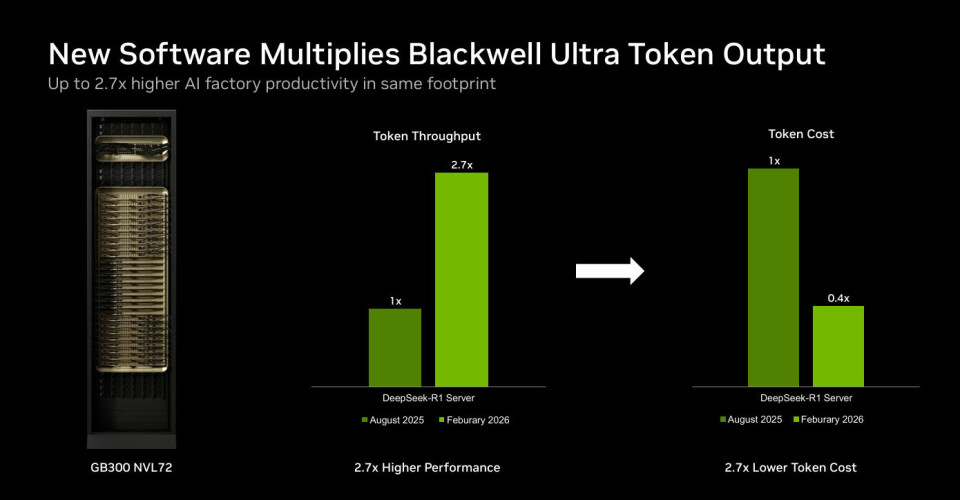
“In just the past six months, we have been able to
nearly triple our performance on DeepSeek-R1, which is a very popular reasoning
model being used in quite a number of places,” Salvatore said, noting that such
performance improvements translate into reduced costs and better scale. “Being
able to perform at scale, it becomes hugely important in terms of thinking
about token cost, because in order to service that many users, you have to be
cranking out a whole lot of tokens. In order to do that, you have to do it in a
way that’s cost-effective.”
Nvidia’s work in software is key to the improved results,
Salvatore said. That includes both what Nvidia is doing in-house as well as its
embrace of open inference frameworks, like TLLM and SGLang.
Inside Nvidia, he pointed to Dynamo, the inference framework
that allows for disaggregated serving, which splits the prefill and decode
stages of inferencing among multiple GPUs to optimize resource utilization,
which drives down the cost of tokens. In the DeepSeek-R1 Interactive benchmark,
the Nvidia-powered system reached 250,634 tokens generated per second, which
brought down the cost to 30 cents per 1 million tokens generated.

He also stressed improvements in TensorRT-LLM, an open
library that accelerates LLM inferencing on its GPUs through such capabilities as
parallelism techniques and multi-token prediction, which enables language
models to learn to predict multiple future tokens simultaneously, rather than
just the next single token.
In CUDA, another optimization is kernel fusion, where Nvidia
is “able to take several kernels and bring them together to make one slightly
larger kernel, which can dramatically speed up all the work that all those
kernels would have done individually,” Salvatore said. “In a similar way, we
can sometimes overlap kernels, where before one kernel completes its work,
another one can kick its work off. And again, bringing them together a little
bit helps to speed up end-to-end processing time.”
Nvidia will always be first and foremost, known
for its big, powerful, and expensive GPUs. That said, executives will continue
to tout the co-design story, noting that ongoing software improvements and such
offerings as reference architectures and AI factory designs will enable those
chips and – despite their cost – make using them a cost advantage.