
Back in December, the Annapurna Labs chip division of Amazon Web Services showed off a preview of its Graviton5 Arm server CPU, and we got some hints about what this chip might look like. This week, the Graviton5 is shipping in new M9g and M9gd instances, and AWS has given us some more details about the Graviton5, filling in some blanks.
Right off the bat, the block diagram that AWS showed during the re:Invent conference seven months ago was not accurate. It showed a monolithic die with 96 pairs of “Poseidon” Neoverse V3 cores. As it turns out, the Graviton5 chip is comprised of four CPU blocks, each with their own 48 V3 cores and the associated memory and I/O controllers. This looks like AWS picked up a block of the Poseidon Compute Subsystem chip that Arm Holdings created and is using in its own AGI CPU and cut it back from 64 cores to 48 cores and used the Arm die-to-die interconnect to make a Graviton5 socket with 192 V3 cores, a dozen DDR5 memory controllers, and eight PCI-Express 6.0 controllers that I think have 96 lanes and that support the CXL 3.0 memory extension protocol.
This latter bit will be important for in-memory databases or workloads that need more memory capacity than AWS can affordably put on a Graviton5 socket. (Fatter memory sticks cost increasingly more as you add capacity to the DIMM – it scales exponentially, not linearly. So you go with the skinniest memory that meets your capacity needs and you always fill all the memory slots to get maximum memory bandwidth against that capacity.)
You can see the four individual Graviton5 chiplets here:

There are four D2D interconnects linking the four chiplets into a virtual processor, and those links run at 420 GB/sec. These interconnects burn a lot of energy, but by using four chiplets, the cost of each chiplet is lower because the yield is much higher for a smaller chip then it would be for a monolithic design pushing up against reticle limits at Taiwan Semiconductor Manufacturing Co. This lower per chiplet cost is mitigated by a switch from 4 nanometer processes used with the Graviton4 chip to the much more expensive but transistor dense and more power efficient 3 nanometer process.
I estimate that the Graviton4 with 96 cores had 73 billion transistors, and for the first time AWS created a two-socket NUMA machine to get single-node performance akin to the Graviton5 that was two years into the future when Graviton4 was revealed in November 2023.
The Graviton4 had essentially the same architecture as the Graviton3, with a central, monolithic core chiplet surrounded by separate memory and I/O controller chips linked to it. Graviton3 had 64 “Zeus” V1 cores and Graviton4 had 96 “Demeter” V2 cores.
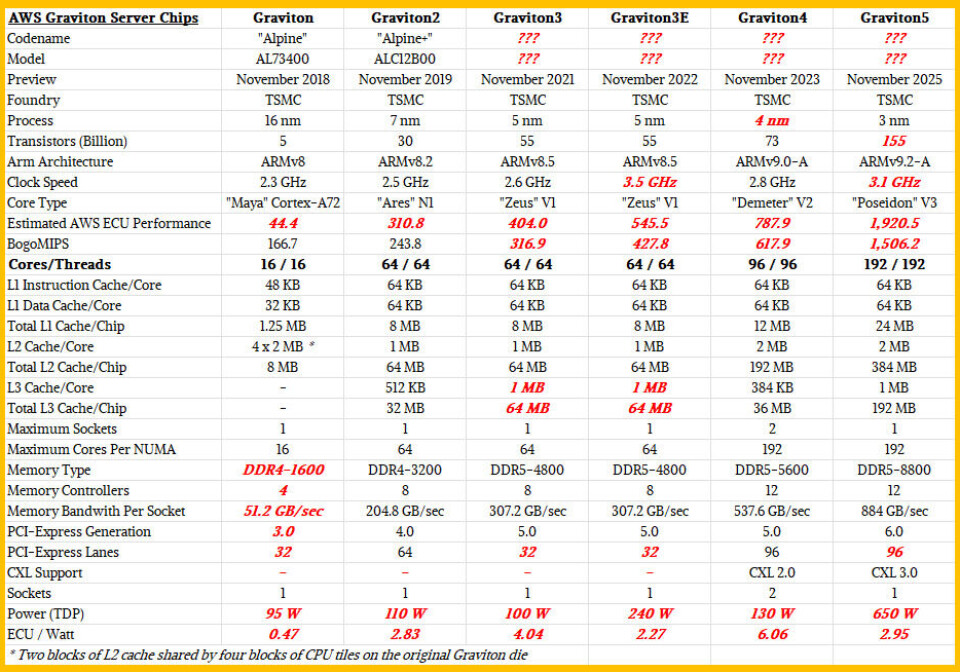
As you can see from the table above, the L1 cache and L2 cache have risen linearly with core count, but AWS has increased the L3 cache faster than the core count. The Graviton5 has 2 MB of L2 cache per core, for a total of 384 MB of L2 cache across those 192 cores, but it has 384 MB of L3 cache per core, twice that of the Graviton5.
Between the increased L3 cache, the faster clock speeds on the V3 cores and the DDR5 memory, and the D2d interconnects between the four chiplets in the Graviton5 socket radically increase the wattage of the Graviton5. I think it weighs in at around 650 watts, which means the performance per watt is half that of the Graviton4. But you get 2.4X more performance per socket with Graviton5, and even comparing the Graviton4 node with two chips in a NUMA shared memory configuration, a single Graviton5 has 25 more raw throughout with only a single chip.
This is all fair tradeoffs given the need for responsive systems to support databases and agentic AI, which need low latency more than they need low heat.
Here is how the M9g instances using Graviton5, which do not have local flash storage, stack up against their R8g and X8g predecessors based on Graviton4, which also do not have local flash in the node:

And here is how the instance pricing and performance stacks up against on demand pricing for the instance for a year:
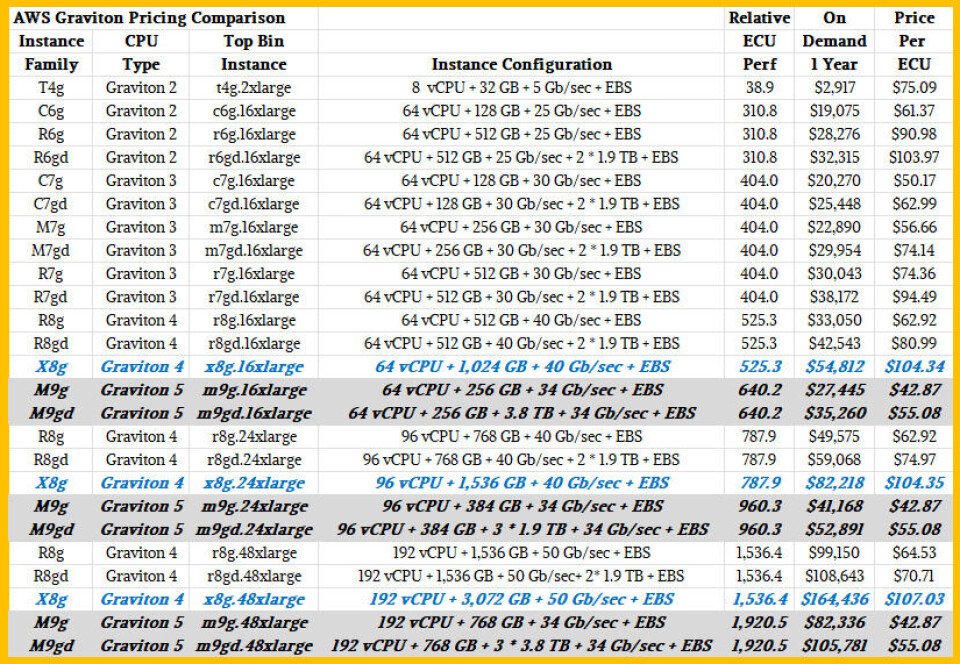
The instance savings plan pricing for the M9g and M9gd instances (the latter adds local flash) and the X8g instances have not been announced publicly for some reason, but there is compute instance pricing, which is a little bit less aggressive on the price cuts but which is more flexible in terms of converting to other instances within datacenters and across regions. On demand pricing is shown above.
What pops out immediately is that AWS is charging about half the price for M9g instances as it does for the X8g instances, and that stands to reason since the M9g instances have a quarter or a half of the memory capacity. (It varies by instance within each family.) This is the immediate impact of the DRAM and flash memory crunch. AWS has to be less generous with flash capacity as well in the variants that have local storage. Compute is cheap, memory is not.
Here is a price/performance table across the early Graviton2 and Graviton3 instances, which were not all that impressive by comparison to the Graviton4 and Graviton5 instances, which do pack a wallop. The M9g instances deliver between 31.9 percent and 33.6 percent better bang for the buck than the most equivalent R8g instances with the same vCPU counts, and the M9gd instances with local flash deliver between 22.1 percent and 32 percent better price/performance than the R8gd instances. The high memory X8g instances are very pricey. You have to really need that large memory footprint to pick this instance.
You might be thinking that the new M9g and M9gd instances based on Graviton5 are a little skimpy on the memory compared to their R8g and R8gd predecessors using the Graviton4 CPU. The capacity on the Graviton5 instances is a quarter to a half that of the Graviton4 instances, but for bandwidth sensitive workloads this capacity may not matter as much. We strongly suspect that there will be heavier-memoried X9g instances in the not too distant future that add more memory, but expect to pay a hefty premium for that extra memory given the cost of DRAM these days. Moreover, AWS is using the fastest DRAM available in the DDR5 form factor, at 8.8 GHz speeds. These Graviton5 instances make up in bandwidth what they might be lacking in capacity.
Some of this extra memory cost might be mitigated by CXL 3.0 memory extenders, and I would not be surprised if AWS has created a shared memory appliance in its Graviton5 racks to deliver this function. I do not think CXL 3.0 memory extenders will be used in the node with PCI-Express 6.0 slots, but that is just because that is more boring than a rackscale memory appliance for extending and sharing DRAM.