
Here
is how you know that GenAI training and GenAI inference are very different
computing and networking beasts, and diverging more with each passing day:
Google has just forked its Tensor Processing Unit, or TPU, designs for these
two workloads, the very first time in more than a decade that TPU systems of
the same generation were truly architecturally distinct from each other.
To
be fair, Google has had versions of prior TPUs, specialized and homegrown AI
accelerators that the search engine, advertising, media mogul, and now AI model
maker first put into the field way back in 2015. Google got into the TPU racket
because there was no way machine learning algorithms could be added to its
applications using CPUs or GPUs without doubling its datacenter footprint. But a
lot of the time these different TPUs were just bin sorts on a designs that were
primarily aimed at AI training, with the lower bin parts being used for
inference. All of this machine learning was much simpler than the processing
used in GenAI mixture of expert models.
As
Nvidia’s $20 billion acquire of Groq last December demonstrated and as
Nvidia co-founder and chief executive officer Jensen
Huang highlighted in his keynote at GTC 2026 back in March, if you want low
latency inference response time – the kind that agentic AI demands, not the
kind of batch processing that chattybots talking to people can get by with – then
you need something that chews on tokens really well (a GPU or a TPU as we have
known it) and then something else that can spit out tokens wicked fast and then
move on to the next query.
The
first workload is called prefill, and the same kind of machinery that can do
prefill can also do GenAI training, which is sometimes called pre-training to
distinguish this model weight creation process from reinforcement learning and
other kinds of AI model tuning. The second workload is called decode, and it
means instead of chewing on tokens to either understand a query and its context
or trying to find the statistical graph of linkages between tokens in a corpus
of data, the system is spitting out tokens for the answers to a query in
whatever modality the GenAI model supports.

You
will get different opinions on just how different the architectures have to be
for the prefill and decode stages. While the new “Sunfish” TPU 8t for training
and recommendation engines (made with the help of Broadcom and shown on the
left above) and the new “Zebrafish” TPU 8i for inference and reasoning (made with
MediaTek and shown on the right) are distinct, they share many components in
their architecture. Under normal circumstances, when Google might not want to try
to do capacity planning across its datacenter fleet by splitting its distinct
hardware, it might have just added more TensorCores to the TPUs, added the
right amount of SparseCores, and added the new Collectives Acceleration Engine,
made one chip, had some of the silicon be dark depending on the workload, and
ended it there.
But
not only do GenAI training and inference (and the other workloads each
respective TPU 8 chip is handling) have different needs when it comes to
processing, they have very different needs for SRAM memory capacity and HBM
memory and memory bandwidth. (One size does not fit all, as Nvidia was well
aware, which is why we had a “Blackwell” B200 GPU for training and inference
and a B300 for inference, just to give one example.) Moreover, GenAI inference and
training have very different network needs, which is why Google has cooked up a
new datacenter fabric codenamed “Virgo” and why it is offering different scale
and topologies for training and inference workloads.
It
is not so much that the TPU 8t and TPU 8i are distinct, but that the systems
built from them are also distinct.
To
get rolling on this deep dive, here is the monster comparison table that shows
every TPU that Google has announced since 2015:
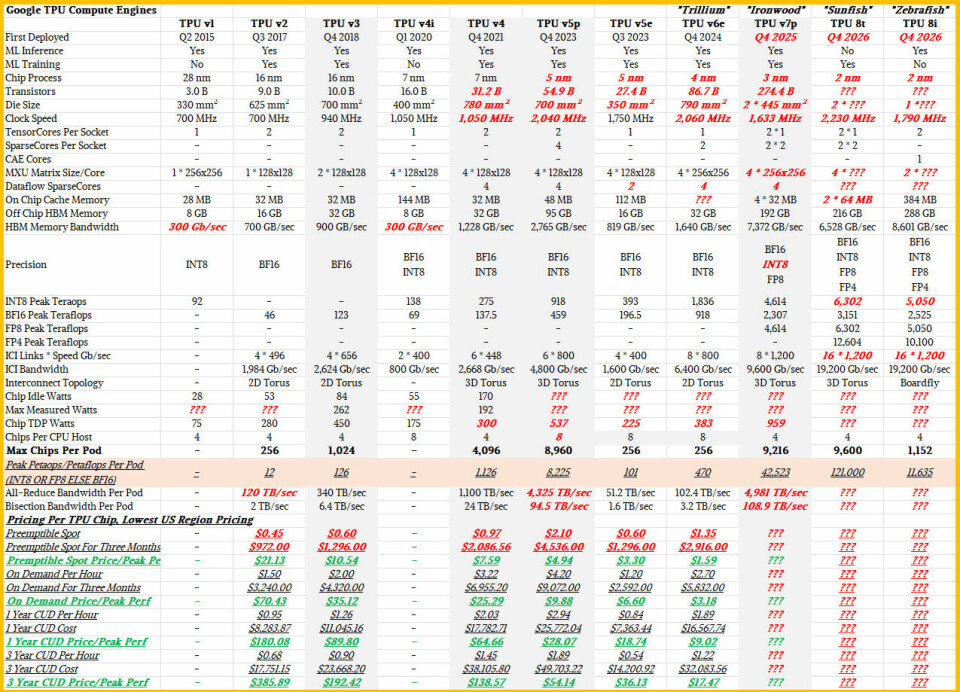
As
usual, items in black are things that we know from blogs and papers, and things
in bold red italics are things we are making informed guesses about. This table
encapsulates the data from several different blog posts as well as the
presentation by Amin Vahdat, chief technologist and senior vice president of AI
and infrastructure at Google. There are many things we do not know yet, and we
suspect many of the missing details will be revealed in a Hot Chips paper this
August, if not before then at a venue of Google’s choosing.
Pricing
for the prior “Ironwood” TPU v7e TPU instances and the not-yet-shipping TPU 8
instances have not been announced as yet, which is a shame. This is a
price/performance per watt story, and we can’t do most of the math in that
simple equation because of the missing data. But what is clear is that the cost
per unit of useful work has to come down. What Google has said publicly so far
is that the Sunfish TPU 8t has 2.7X better bang for the buck on AI training
than the Ironwood TPU v7e, the Zebrafish TPU 8i has 1.8X better performance per
watt than the Ironwood TPU v7e, and that both chips deliver 2X better
performance per watt.
We
look forward to seeing how these numbers were ginned up, and we think they are
real-world performance, not based on peak theoretical throughput as shown in
the monster above.
Let’s
Take A Look Under The Hood
Unlike
GPUs, which have dozens to tens of thousands of different kinds of cores, the
TPUs cram a lot of capability in a few cores and accelerators to get the AI processing
done. The TPU 8t and TPU 8i chips have different numbers of TensorCores, which
include both matrix and vector math units, and are different in the choice of
SparseCore or CAE accelerators that are included in the package, as well as how
much SRAM and HBM memory they have. They probably have different clock speeds
and thermals, too. But if we were Google we would push each TPU 8 chip to the
thermal limit of the TPU 8 system design, and get there by dialing up and down the
clock speed for either chip. But it may turn out that the bigger TPU 8i burns a
lot more juice and delivers the same amount of a performance boost for
inference so the increase in performance per watt for both the Sunfish 8t and
the Zebrafish 8i come to the 2X number cited above from Google.
The
TPU 8t package has two compute dies, one I/O die at the top, two other chiplets
left and right of the I/O die, and two columns of HBM3e – not HBM 4, which is
important – on each side of the compute die. The choice of HBM3e means Google
is doing a price/performance optimization on the memory. The HBM3e stacks are twelve
DRAM chips high (there is an error in the block diagram below), and the six
stacks provide 216 GB of capacity and 6,528 GB/sec of bandwidth. If you compare
to the Ironwood TPU, the Sunfish 8t chip has 12.5 percent more memory but it
delivers 11.5 percent lower bandwidth, which means it is running slower to
improve yield and lower cost.
Here
is the block diagram for the Sunfish TPU 8t chiplet:
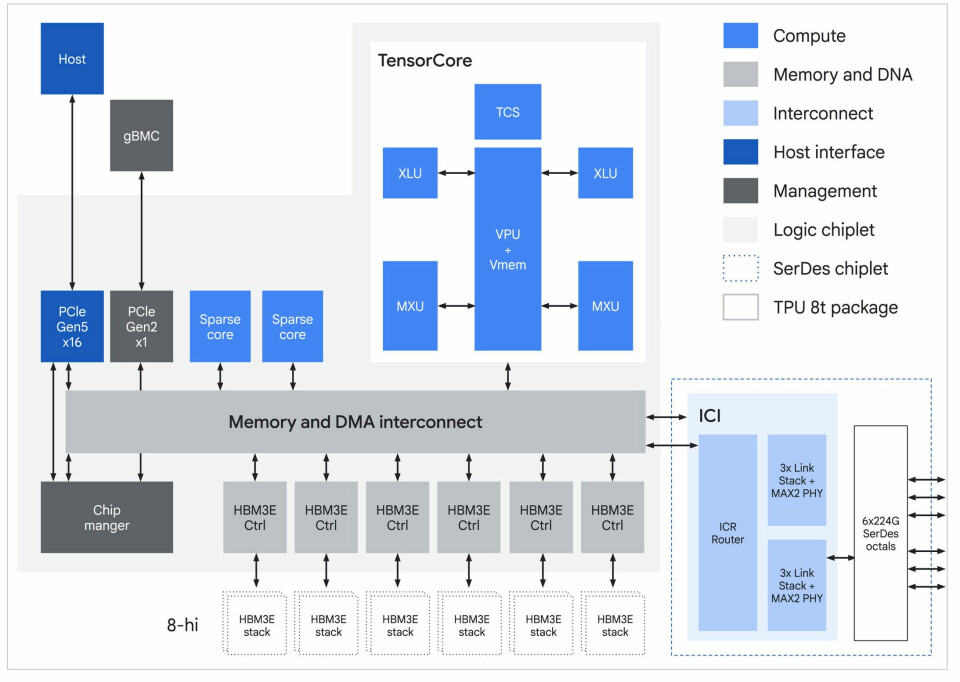
The
Sunfish package has 128 MB of SRAM memory, meaning 64 MB on each core chiplet
in the package. This is the same aggregate SRAM per package as the Ironwood TPU
v7e. We do not know the aggregate bandwidth of this SRAM.
The
TPU 8t TensorCore has a big wonking vector unit and two matrix math units, but
there are some microarchitecture changes that are not obvious in the block
diagram above.
“TPU
8t is a powerhouse optimized for training,” explained Vahdat in his keynote. “We
have redefined performance capability by moving block scale multiplication
directly inside the MX units. This native quantization eliminates VPU overhead,
delivering nearly three times the compute performance per pod over previous
generations. This allows us to push the absolute limits of model flops
utilization at a massive scale, and reduces the training time in frontier
models. It leverages a breakthrough inter-chip interconnect technology, which
now delivers twice the bandwidth compared to Ironwood, scaling up to 9,600 TPUs
connected with a 3D torus topology.”
Let’s
not get too far ahead of ourselves with the system architecture. Back inside
the Sunfish 8t socket, there is one TensorCore per chiplet and two SparseCores
per chip, for a total of four per socket – just like Ironwood. We think Google
might have jacked up the clock speed to the neighborhood of 2.2 GHz with the
Sunfish 8t chip, which is a 42.6 percent increase over what we guessed was the
Ironwood clock speed. That may seem like a lot, but with a multi-chiplet design,
Google can increase yield on the 2 nanometer process we think it is using for
the two TPU 8 chips and use a lot of the die shrink to crank the clocks and ratchet
up raw performance and through other tweaks, get a lot more of an effective performance
boost.
The
SparseCore chips were initially designed to accelerate recommendation models
that make use of embeddings to make recommendations across classes of users.
The third generation SparseCores in the Ironwood TPU had various algorithms
encoded in them to accelerate financial and scientific calculations, and I do
not know if there are more functions in the TPU 8t SparseCores but suspect this
is so.
We
do not know if the TPU chips include the Dataflow SparseCores that were added
to the TPU v4 through the TPU v7e AI accelerators.
The
Sunfish TPU supports BF16, INT8, and FP8 formats and adds a new FP4 format that
boosts the performance by 2X over FP8 for those portions of the GenAI training
stack that can take a precision cut. The peak FP4 throughput of the Sunfish TPU
8t is 12.6 petaflops, and I presume you cut that in half for peak FP8 oomph and
then cut it in half again for peak BF16 throughput. I do not assume that INT8
performance is equal to FP8 performance, but it probably is for both TPU 8
chips.
The
Sunfish TPU 8t uses the same 3D torus interconnect as the Ironwood TPU v7e, but
it has been stretched to 9,600 TPUs in a single memory domain pod compared to
the 9,216 for the Ironwood pod.
That
brings us to the inference side of the TPU house and the Zebrafish TPU 8i.
The
Zebrafish 8i chip is a biggie, and a lot of that is because it has 384 MB of
SRAM cache across the single compute die in the 8i package. Once you have to
make a big SRAM, you might as well plunk twice the number of TensorCores on the
package and balance it out. And that is precisely what Google did. The
effective cash per TensorCore has risen by 3X compared to the Sunfish 8t and
the Ironwood v7e accelerator.
Here
is the block diagram of the Zebrafish TPU 8i chip:
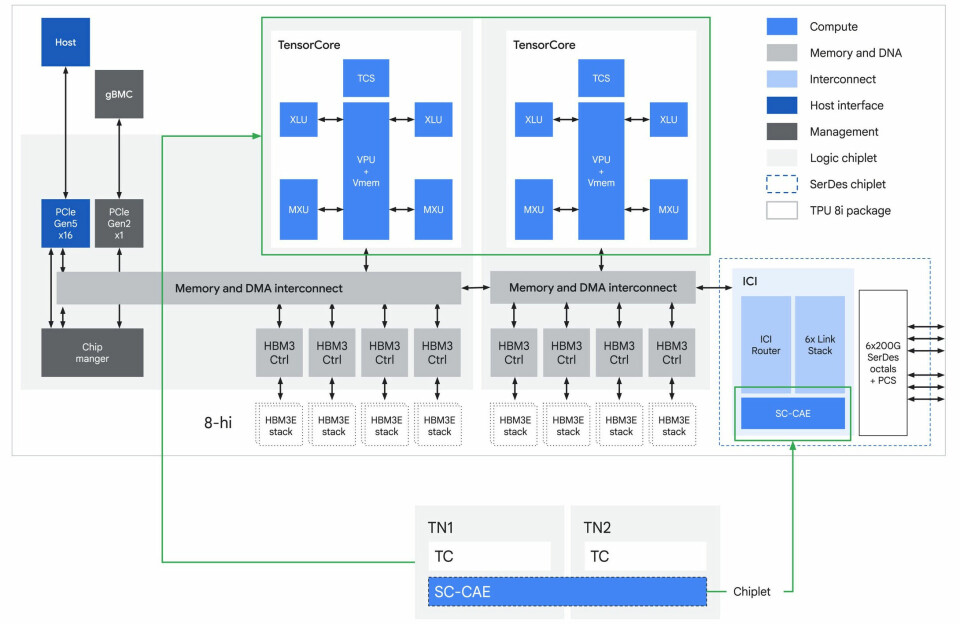
The
Zebrafish 8i chip has two TensorCores but no SparseCores. It does have the new
Collectives Acceleration Engine, or CAE, which is kind of collectives offload
engine. Here is how Google described it in the technical blog:
“To
solve the sampling bottleneck, TPU 8i uses the CAE, which aggregates results
across cores with near-zero latency, specifically accelerating the reduction
and synchronization steps required during auto-regressive decoding and
“chain-of-thought” processing. For each TPU 8i chip, there are two
Tensor Cores (TC) on-core dies and one CAE on the chiplet die, replacing four
SparseCores (SCs) on core dies in previous-generation Ironwood TPU. By
integrating a specialized CAE, TPU 8i further reduces the on-chip latency of
collectives by 5X. Lower latency per collective operation means less time spent
waiting, directly contributing to higher throughput required to run millions of
agents concurrently.”
I
look forward to finding out more about how this CAE thingamabob works.
Given
the Zebrafish 8i chip’s focus on inference, Google came up with a new hierarchical
network topology for the interchip interconnect (ICI) that it has used to link
machines at the board level and sometimes at the rack level in its TPU systems.
Both
of these TPU system boards, which have four sockets per board, use Google’s own
Axion Arm server CPUs as hosts. Google has not been precise about which of the two
flavors of Axion it is using – the one based on Neoverse V2 cores or Neoverse
N3 cores. We will try to find out.
With that, in the second part of this story, I will
talk about the networking enhancements in the TPU 8 systems. Stay tuned.